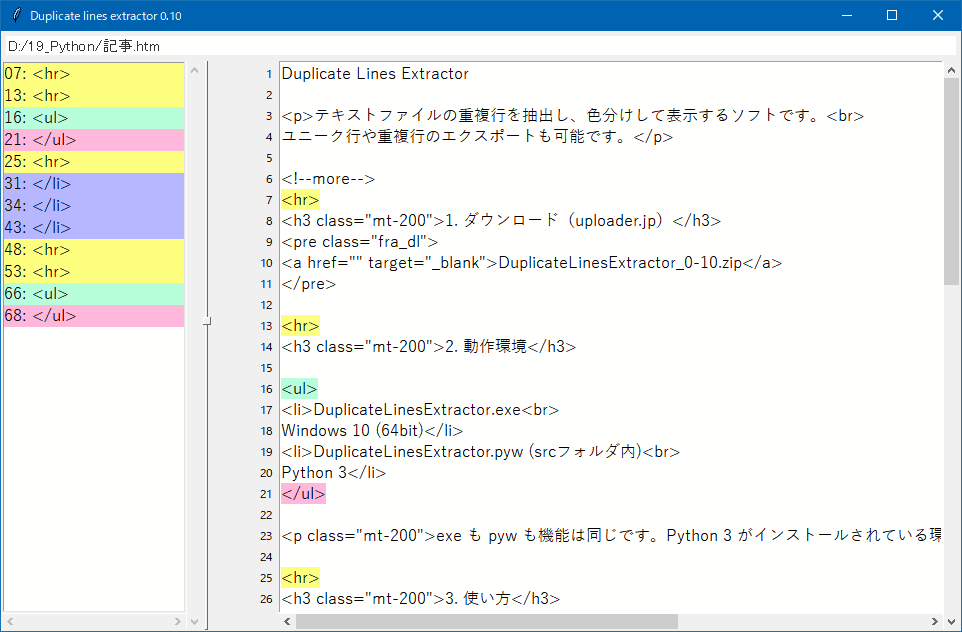
テキストファイルの重複行を抽出し、色分けして表示するソフトです。
ユニーク行や重複行のエクスポートも可能です。
※2019/11/24 version 0.20 に更新。テキストボックスで重複行を選択した際の背景色を変更しました。
1. ダウンロード(uploader.jp)
ファイル内容
- src
- DuplicateLinesExtractor.pyw
- DuplicateLinesExtractor.exe
- LICENSE.txt
- readme.md
2. 動作環境
- DuplicateLinesExtractor.exe
Windows 10 (64bit) - DuplicateLinesExtractor.pyw (srcフォルダ内)
Python® 3.4 以降
zip を解凍し、”DuplicateLinesExtractor.exe” を実行してください。exe の実行に Python は不要です。
src フォルダには、Python 3.4 以降導入下でのみ使える “DuplicateLinesExtractor.pyw” が入っています。exe も pyw も機能は同じですが、pyw の方が起動はわずかに早いです。
3. 使い方
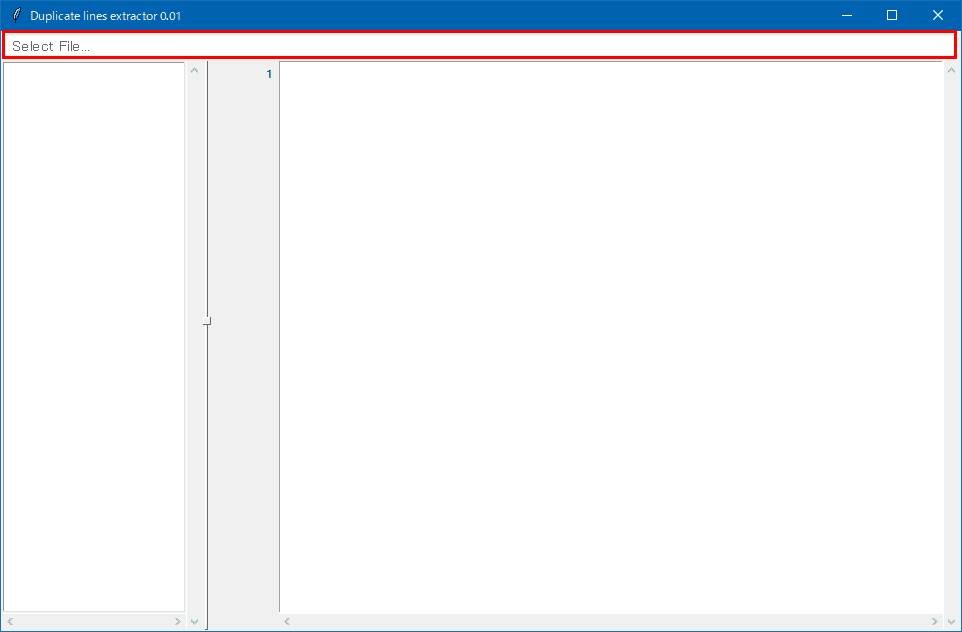
1. ファイルパス欄をクリックするか「Ctrl + s」を押して、ファイルを選択します。
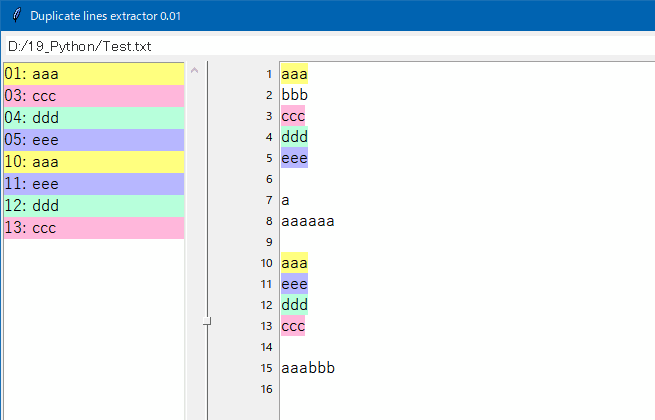
2. 重複行が自動的に色分けして表示されます。
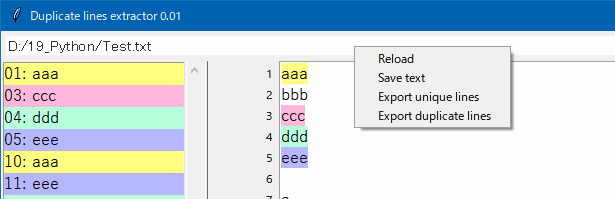
3. ファイルパス欄を右クリックするか「Ctrl + s」を押すと、メニューが表示されます。
- Reload … ファイルを再読み込みします。
- Save text … テキストボックスに表示中の文字列を保存します。
- Export unique lines … 重複を削除したユニーク行をエクスポートします。
- Export duplicate lines … 重複リストを行番号付きでエクスポートします。
改行のみの空行は、重複とは判定しません。ユニーク行をエクスポートする際は、空行を削除せずにそのまま出力します。
ウィンドウの大きさや位置は、ソフトを実行すると作成される “DuplicateLinesExtractor_settings.ini” で指定できます。
4. 更新履歴
- 2019/11/24 (version 0.20) ; テキストボックスで重複行を選択した際の背景色を変更しました。os モジュールの代わりに pathlib モジュール を用いるように変更しました。これにより Python 3.4 以降が必要になりました。機能の変更はありません。
- 2019/10/15 (version 0.10) ; 公開。
5. 補記
5-1. version 0.10
以前、テキストファイルの重複行を抽出し、リスト化するバッチ というものを公開しました。結構負荷が高くて処理に時間がかかっていたのですが、これを Python で書き直したものが今回のソフトです。
処理速度としては、うちのミドルスペックデスクトップPCで3万行のテキスト(1.8MB)が約4秒で表示できます。2013年発売のノートPCでも6秒くらい。1秒当たり5000~7500行の計算になるので、通常用途では十分でしょう。
現状のソースコードは参考にならないと思いますので、あまり見ないようにお願いします。
class とか def とかの使い方がまだまだですし、モジュールを分けたりしたらカッコいいなとは考えつつも、すべて1つのファイル内に記述しています。
1年くらいして見返したら「なんだこれ?」ってなりそうなコードなんですが、プログラミングはとにかく作って覚える派なので、とりあえず大目に見てやってください。
テキストボックスに行番号を付ける方法は公式ドキュメントを見ても全く分からず、以下のサイト様を参考にさせていただきました。
大変感謝しております。
5-2. version 0.20
テキストボックスで重複行を選択した際に、背景色が変わらず分かりにくかった点を修正しました。選択された部分は、やや暗い背景色になります。
また、pathlib モジュールを用いるように変更しました。公式ドキュメントを読んだ印象で、os モジュールよりも将来性がありそうだからです。今後はすべて pathlib にしようと思っています。
class と def の使い方に関しては、ver 0.10 に比べて向上したと思います。まだクラスの分け方やクラス変数の設定に難があると感じていますが、さらに勉強していきたいと思っています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}