テキストファイルの重複行を抽出し、行番号付きのリストとして書き出すためのバッチです。同時に、重複行を削除した整形ファイルも作成することができます。
「重複している行を抽出する」という点が特長で、抽出されたリストを見ながら元のテキストファイルを編集することができます。
※2018/10/11 「!」と「^」だけでなく「」や「”」が含まれるファイルにも対応し、記事をリニューアルしました。
※2018/10/13 完全版の進捗状況の表示方法を変更しました。
※2018/10/16 完全版のみ、重複行がない場合には、作成された空の重複リストを削除するようにしました。
※2019/10/15 この機能を持ったソフトウェアを作成しました。 → Duplicate Lines Extractor
目次
1. 【シンプル版】重複行を抽出するバッチ
まずはコアとなる機能のみを搭載した、シンプル版のバッチを挙げておきます。
@echo off
rem ----------設定ここから----------
rem 重複リストの行番号の桁数 (0~8)
set /a Digit=4
rem 重複行を削除した整形ファイルの出力 (0:しない、1:する)
set /a ExpUnique=0
rem ----------設定ここまで----------
if "%~1" == "" (
echo このバッチ上に、処理したいファイルをドラッグ^&ドロップしてください。
pause > nul & exit /b
)
echo 重複行を抽出中...
if "%Digit%" == "" (set /a Digit=8)
if %Digit% lss 0 (
set /a Digit=9
) else if %Digit% gtr 8 (
set /a Digit=1
) else (
set /a Digit=9 - %Digit%
)
set /a Line=100000001
set LineNo=
set LineStrTmp=
set Duplicate=%~dp1%~n1_duplicate.txt
set Unique=%~dp1%~n1_unique.txt
type nul > "%Duplicate%"
type nul > "%Unique%"
for /f "tokens=* delims=0123456789" %%i in ('findstr /n "^" %1') do (
set LineStr=%%i
setlocal enabledelayedexpansion
set LineStr=!LineStr:~1!
if not "!LineStr!" == "" (
set LineStrTmp=!LineStr:*\\*=\!
set LineStrTmp=!LineStrTmp:\=\\!
set LineStrTmp=!LineStrTmp:"=\"!
)
findstr /x /c:"!LineStrTmp!" "%Unique%" >nul 2>&1
if !ERRORLEVEL! neq 0 (
(echo.!LineStr!) >> "%Unique%"
) else (
if %Digit% neq 9 (set LineNo=!Line:~%Digit%!: )
(echo.!LineNo!!LineStr!) >> "%Duplicate%"
)
endlocal
if %Digit% neq 9 (set /a Line+=1)
)
if %ExpUnique% neq 1 (del "%Unique%")2. 動作
2-1. 元のテキストファイルをバッチ上にドラッグ&ドロップする
動作方法は、バッチ上にファイルをドラッグする形にしました。重複行を抽出したいファイルをバッチファイルの上にドラッグすれば、元のファイルと同じフォルダ内に以下の2つが作成されます。
- 元ファイル名_Duplicate.txt … 重複行を抽出したリスト
- 元ファイル名_Unique.txt … 重複行を削除して整形したファイル
重複リストは必ず作成されます。整形ファイルを作成するかどうかは、設定の「ExpUnique」で指定できます。
このバッチでは、テキストに「!」「^」「」「”」の文字が含まれていても動作します。
サーバーパスに使われるような、連続する「\」が行頭と行中にある場合は、重複行であれば抽出されます。末尾が「\」で終わる行にだけは対応できず、重複行であっても抽出されません。
2-2. バッチの設定
設定項目は2つです。
- Digit … 重複リストの行番号の桁数を、「0」~「8」 の数値で指定します。
- ExpUnique … 整形ファイルを出力するかどうかを指定します。「0」で出力しない、「1」で出力する設定になります。
重複リストの行番号は、「0001: 抽出行テキスト」の形式で付加されます。桁数はデフォルトで4桁になっており、元のテキストが9999行までのファイルならこれで対応できます。最大8桁まで自由に指定してください。桁数に「0」を指定すると行番号とコロンの部分はなくなり、「抽出行テキスト」のみでリストが作成されます。
「ExpUnique」はデフォルトで「1」になっています。整形ファイルが不要なら「0」にしてください。
2-3. 動作例
次のようなテキストファイルで、実際の動作を示しておきます。
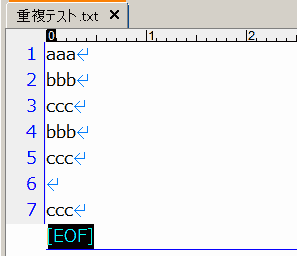
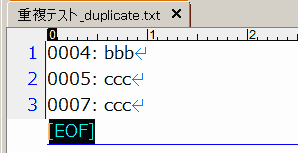
重複リストは以下のようになります。重複していた行が、元ファイルの行番号とともに出力されます。
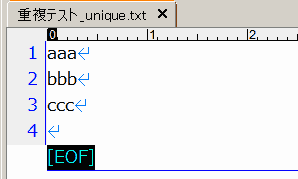
整形ファイルは以下のようになります。改行のみの空行は、そのまま整形ファイルに出力されます。
3. ポイント解説
3-1. 「%1」が空の場合の処理 (10行目)
if "%~1" == "" (
echo このバッチ上に、処理したいファイルをドラッグ^&ドロップしてください。
pause > nul & exit /b
)今回は元のファイルをバッチ上にドラッグしますので、「%1」に元のファイルのパスが入ります。単にバッチファイルをダブルクリックされたときの対処として、「%1」が空の場合はメッセージを出して終了させています。
この判定をする際、「if “%~1” == “”」としています。「if %1 == “”」と書くと、「%1」が空の場合に強制終了してしまい、エラーメッセージを表示することができなくなります。
3-2. 重複リストと整形ファイルの初期化 (33行目)
type nul > "%Duplicate%"
type nul > "%Unique%"出力先となる「~_Duplicate.txt」と「~_Unique.txt」が先に存在している場合も含め、2つのファイルを初期化しているのがこの部分です。
「type」は本来ファイル内容を表示するコマンドですが、「nul」を指定することで何もない文字列を表します。これを「>」で書き出すことにより、ファイルがなければ新規作成されますし、あれば内容を消去することができます。
これを「echo」でやろうとすると「ECHO は <OFF> です。」になってしまうので type を使います。
3-3. 1行ずつ取り出して処理する (36行目)
for /f "tokens=* delims=0123456789" %%i in ('findstr /n "^" %1') do (
set LineStr=%%i
setlocal enabledelayedexpansionここはすごく説明しづらいので簡単に…。
「findstr ~」の部分で元ファイルの改行位置 (“^”) ごとに行番号を付けて (/n) 、1行ずつ「%%i」に渡します。このとき「delims」で数字を区切りとしているため、実際には数字が除かれて「:行テキスト」の形式になります。
それを「LineStr」変数に入れてから以降の処理を行っています。
大事なのは「setlocal ~」の位置です。「LineStr=%%i」の部分を「setlocal ~ endlocal」の外に記述しないと、行テキストに「!」や「^」が含まれていた場合に正しい文字列を取得できません。
1行判定するごとに「setlocal」を繰り返すのもどうかと思いますが、どんな文字列でも正しく取得できるようにしておく方が重要だと思います。
3-4. 重複しているかどうか判定して書き出す (40行目)
if not "!LineStr!" == "" (
set LineStrTmp=!LineStr:*\\*=\!
set LineStrTmp=!LineStrTmp:\=\\!
set LineStrTmp=!LineStrTmp:"=\"!
)
findstr /x /c:"!LineStrTmp!" "%Unique%" >nul 2>&1
if !ERRORLEVEL! neq 0 (
(echo.!LineStr!) >> "%Unique%"
) else (
if %Digit% neq 9 (set LineNo=!Line:~%Digit%!: )
(echo.!LineNo!!LineStr!) >> "%Duplicate%"
)if not 分岐で、「LineStr」の文字列に「\」と「”」がある場合の対処をしています。
最初が「\\」と連続している場合への対処で、行頭と行中であればこれで対応できます。行末にあるときだけは対応できないのですが、行末に「\\」がくるようなテキストはそうそうないと思われますので我慢しています。
2つ目と3つ目は、それぞれ「\」と「”」への対処です。
これらの対処をした文字列を「LineStrTmp」変数に格納しています。
続いて「LineStrTmp」の文字列が「Unique (整形ファイル)」にあるかどうか判断します。
文字列があればエラーレベルは0で、重複行となります。以降の if 分岐で行番号を付けて「Duplicate (重複リスト)」に書き出します。
一方、文字列がない場合は整形ファイルに追記していきます。
これらの操作により、元ファイルを1行ごとに判定し、重複リストあるいは整形ファイルのどちらかに書き出して振り分けています。
実は整形ファイルも必ず作成されているのでそのまま残しても良いのですが、「元ファイルの重複行を知りたい」というだけの用途だと整形ファイルは邪魔なので、設定で制御できるようにしています。
4. 【完全版】行番号桁数の自動設定、および進捗状況の表示も行うバッチ
重複リストの行番号の桁数を、テキストファイルの行数から自動で設定するバージョンを作成しました。例えば200行のテキストファイルなら、3桁の行番号で重複リストが作成されます。
従来通り Digit の値を変更することで、8桁までなら自由に設定することもできます。初期設定は「1」で1桁なのですが、必要な桁数まで自動で引き上げるようになっています。
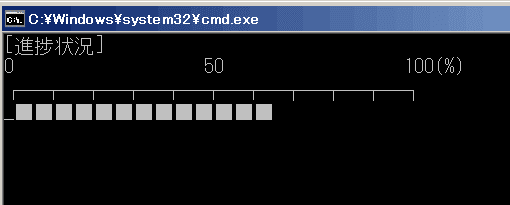
それから、抽出の進捗状況をコマンドプロンプトの画面内に表示するようにしています。1000行を超えるようなテキストファイルの抽出だと少し時間がかかりますので、視覚的に進捗を見られる方が安心です。
表示のために余計な処理をしていることは確かなので、それを避けたい場合はシンプル版をお使いください。
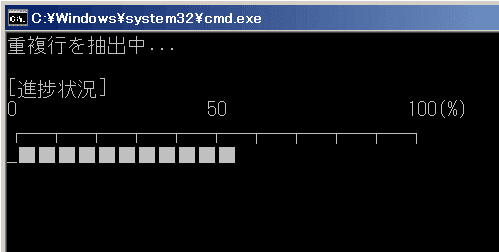
また、この完全版のみ、処理後に自動で重複リストを開くようにしています。重複行がなくリストが空の場合は、コマンドプロンプトの画面にメッセージを表示して終了します。空の重複リストは自動で削除されます。
@echo off
rem ----------設定ここから----------
rem 重複リストの行番号の桁数 (0~8)
set /a Digit=1
rem 重複行を削除した整形ファイルの出力 (0:しない、1:する)
set /a ExpUnique=0
rem ----------設定ここまで----------
if "%~1" == "" (
echo このバッチ上に、処理したいファイルをドラッグ^&ドロップしてください。
pause > nul & exit /b
)
echo 重複行を抽出中... & echo. & echo [進捗状況]
echo 0 50 100(%%) & echo ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
set /p Bar=_< nul
if "%Digit%" == "" (set /a Digit=0)
if %Digit% lss 0 (
set /a Digit=0
) else if %Digit% gtr 8 (
set /a Digit=8
)
for /f "delims=: tokens=2" %%i in ('find /c /v "" "%~nx1"') do (
set /a NOL=%%i
)
if %NOL% equ 0 (
echo. & echo. & echo エラー: 空のテキストファイルです。処理を中止します。
pause > nul & exit /b
) else if %NOL% lss 20 (
set /a PreBar=20 - %NOL%
setlocal enabledelayedexpansion
for /l %%i in (1,1,!PreBar!) do (set /p Bar=■< nul)
endlocal
)
if %Digit% equ 0 (goto Export)
set /a DOL=0
set NOLtmp=%NOL%
:Loop
if not "%NOLtmp%" == "" if %DOL% lss 8 (
set NOLtmp=%NOLtmp:~1%
set /a DOL+=1
goto Loop
)
if %DOL% gtr %Digit% (
set /a Digit=%DOL%
)
:Export
set /a Digit=9 - %Digit%
set /a Line=100000001
set /a Prog=0
set /a Mag=1
set LineNo=
set LineStrTmp=
set Duplicate=%~dp1%~n1_duplicate.txt
set Unique=%~dp1%~n1_unique.txt
type nul > "%Duplicate%"
type nul > "%Unique%"
for /f "delims=0123456789 tokens=*" %%i in ('findstr /n "^" %1') do (
set /a Prog+=1
set LineStr=%%i
setlocal enabledelayedexpansion
set LineStr=!LineStr:~1!
if not "!LineStr!" == "" (
set LineStrTmp=!LineStr:*\\*=\!
set LineStrTmp=!LineStrTmp:\=\\!
set LineStrTmp=!LineStrTmp:"=\"!
)
findstr /x /c:"!LineStrTmp!" "%Unique%" >nul 2>&1
if !ERRORLEVEL! neq 0 (
(echo.!LineStr!) >> "%Unique%"
) else (
if %Digit% neq 9 (set LineNo=!Line:~%Digit%!: )
(echo.!LineNo!!LineStr!) >> "%Duplicate%"
)
set /a Calc=!Prog! * 20
set /a Calc/=%NOL%
if !Calc! geq !Mag! (
set /p Bar=■< nul
endlocal
set /a Mag+=1
) else (
endlocal
)
if %Digit% neq 9 (set /a Line+=1)
)
if %ExpUnique% neq 1 (del "%Unique%")
set /p FirstLine=<"%Duplicate%"
if "%FirstLine%" == "" (
del "%Duplicate%"
echo. & echo. & echo 重複行はありませんでした。処理を終了します。
pause > nul
) else (
start "" "%Duplicate%"
)
{kind=link}